Subset & Index
ไม่ว่า dataset จะมีลักษณะ array, matrix, หรือ dataframe เราสามารถ subset หรือพูดง่าย ๆ คือการตัดเฉพาะข้อมูลที่เราจะใช้ออกมาได้ การ subset จะมีการเขียนคำสั่งแตกต่างไปบ้างขึ้นอยู่กับลักษณะ dataset แต่สิ่งที่สำคัญที่สุดคือการเรียนรู้การระบุพิกัดของข้อมูล หรือที่เราเรียกว่า indexing
การระบุพิกัดของข้อมูล (indexing)
ในการฝึกนี้เราจะใช้ matrix ที่เราสร้างขึ้นมาเอง
matrix <- matrix(1:6, 6)
## [,1] [,2] [,3] [,4] [,5] [,6]
## [1,] 1 1 1 1 1 1
## [2,] 2 2 2 2 2 2
## [3,] 3 3 3 3 3 3
## [4,] 4 4 4 4 4 4
## [5,] 5 5 5 5 5 5
## [6,] 6 6 6 6 6 6
การเรียง index ของ R จะเป็นการเรียงแบบ [เลขแถว, เลขคอลลัมภ์] นั่นหมายความว่า ถ้าจะเรียกข้อมูลแถวที่ 3 บรรทัดที่ 4 ออกมา เราจะเขียนคำสั่งว่า ชื่อ file[3,4]
แต่หากว่าต้องการข้อมูลทั้งแถวหรือทั้งคอลลัมภ์ เราสามารถเรียกได้โดยการไม่ใส่ข้อมูลใด ๆ ลงใน [ , ] เช่น
- ต้องการแถวที่ 3 คอลลัมภ์ที่ 4
matrix[3,4]
## [1] 3
- ต้องการคอลลัมภ์ที่ 4 ทุกแถว
matrix[ ,4]
## [1] 1 2 3 4 5 6
- ต้องการแถวที่ 3 ในทุกคอลลัมภ์
matrix[3, ]
## [1] 3 3 3 3 3 3
คำสั่งนี้ยังนำไปใช้กับ dataframe หรือ table ได้เลย แต่เนื่องจากความเป็น dataframe ใน R จะบอกชื่อคอลลัมภ์กำกับมาด้วย
- ต้องการแถวที่ 3 คอลลัมภ์ที่ 4
dataframe[3, 4]
## [1] 3
- ต้องการคอลลัมภ์ที่ 4
dataframe[ ,4]
## [1] 1 2 3 4 5 6
- ต้องการแถวที่ 3
dataframe[3, ]
## X1 X2 X3 X4 X5 X6
## 3 3 3 3 3 3 3
การเลือกพิกัดอย่างเฉพาะเจาะจง
นอกจากการเลือกพิกัดตามคำสั่งด้านบนแล้ว หากข้อมูลมีความหลากหลายมาก ๆ เราสามารถเลือกตัวแปรที่ต้องการ แถวที่ต้องการโดยใช้คำสั่ง c() (มาจากคำว่า combine) กำกับ และ : สำหรับการเรียกข้อมูลที่ต่อกัน
ในส่วนนี้เราจะดึง dataset ที่มาจาก package ชื่อ coronavirus และ data ชื่อ coronavirus ออกมา
install.packages("coronavirus")
library(coronavirus)
data <- data("coronavirus")
การเลือกโดยการระบุพิกัดมีความยืดหยุ่นมากใน R เช่น หากต้องการเรียกแถวที่ 1 ถึง 200 และ เรียกทุก ๆ คอลลัมภ์ เราสามารถใช้ [1:200, ] กับ dataset ได้เลย แต่ถ้าหากว่าเราต้องการข้อมูลที่แถว 1:10, 15, 16, 19, และ 200 ในทุก ๆ คอลลัมภ์ เราสามารถเขียน [c(1:10, 15, 16, 19, 200), ]จะพบว่าจำนวนแถวจะตรงกับแถวที่เราต้องการ
- ต้องการข้อมูลแถวที่ 1 - 200 ในทุกคอลลัมภ์ (ปกติจะขี้นมา 200 แถวค่า แต่ว่าเพื่อเป็นการยกตัวอย่างจึงตัดตรงกลางออก)
Data[1:200, ]
## date province country cases population
## 1 2020-01-22 Alberta Canada 0 4413146
## 2 2020-01-23 Alberta Canada 0 4413146
## 3 2020-01-24 Alberta Canada 0 4413146
## 4 2020-01-25 Alberta Canada 0 4413146
## 5 2020-01-26 Alberta Canada 0 4413146
## 6 2020-01-27 Alberta Canada 0 4413146
## 7 2020-01-28 Alberta Canada 0 4413146
## 8 2020-01-29 Alberta Canada 0 4413146
## 9 2020-01-30 Alberta Canada 0 4413146
## 10 2020-01-31 Alberta Canada 0 4413146
## .........
## 176 2020-07-15 Alberta Canada 82 4413146
## 177 2020-07-16 Alberta Canada 120 4413146
## 178 2020-07-17 Alberta Canada 105 4413146
## 179 2020-07-18 Alberta Canada 0 4413146
## 180 2020-07-19 Alberta Canada 0 4413146
## 181 2020-07-20 Alberta Canada 368 4413146
## 182 2020-07-21 Alberta Canada 141 4413146
## 183 2020-07-22 Alberta Canada 0 4413146
## 184 2020-07-23 Alberta Canada 247 4413146
## 185 2020-07-24 Alberta Canada 111 4413146
## 186 2020-07-25 Alberta Canada 0 4413146
## 187 2020-07-26 Alberta Canada 0 4413146
## 188 2020-07-27 Alberta Canada 304 4413146
## 189 2020-07-28 Alberta Canada 80 4413146
## 190 2020-07-29 Alberta Canada 133 4413146
## 191 2020-07-30 Alberta Canada 113 4413146
## 192 2020-07-31 Alberta Canada 127 4413146
## 193 2020-08-01 Alberta Canada 0 4413146
## 194 2020-08-02 Alberta Canada 0 4413146
## 195 2020-08-03 Alberta Canada 0 4413146
## 196 2020-08-04 Alberta Canada 303 4413146
## 197 2020-08-05 Alberta Canada 94 4413146
## 198 2020-08-06 Alberta Canada 56 4413146
## 199 2020-08-07 Alberta Canada 134 4413146
## 200 2020-08-08 Alberta Canada 0 4413146
- ต้องการแถวที่ 1-10, 15,16,19 และ 200 ในทุกคอลลัมภ์
Data[c(1:10, 15, 16, 19, 200), ]
## date province country cases population
## 1 2020-01-22 Alberta Canada 0 4413146
## 2 2020-01-23 Alberta Canada 0 4413146
## 3 2020-01-24 Alberta Canada 0 4413146
## 4 2020-01-25 Alberta Canada 0 4413146
## 5 2020-01-26 Alberta Canada 0 4413146
## 6 2020-01-27 Alberta Canada 0 4413146
## 7 2020-01-28 Alberta Canada 0 4413146
## 8 2020-01-29 Alberta Canada 0 4413146
## 9 2020-01-30 Alberta Canada 0 4413146
## 10 2020-01-31 Alberta Canada 0 4413146
## 15 2020-02-05 Alberta Canada 0 4413146
## 16 2020-02-06 Alberta Canada 0 4413146
## 19 2020-02-09 Alberta Canada 0 4413146
## 200 2020-08-08 Alberta Canada 0 4413146
ในการเลือกคอลลัมภ์หรือตัวแปรนั้น จะใช้การเรียกพิกัดแบบเดียวกันกับวิธีด้านบนก็ได้ แต่หากมีชื่อคอลลัมภ์อยู่แล้ว อาจจะสะดวกมากกว่าที่จะเลือกเป็นชื่อโดยใช้ "_____" แทนการเขียนตัวเลข
- ต้องการแถวที่ 1 - 10 ในคอลลัมภ์ชื่อ date, country, cases
Data[1:10, c("date", "country", "cases")]
## date country cases
## 1 2020-01-22 Canada 0
## 2 2020-01-23 Canada 0
## 3 2020-01-24 Canada 0
## 4 2020-01-25 Canada 0
## 5 2020-01-26 Canada 0
## 6 2020-01-27 Canada 0
## 7 2020-01-28 Canada 0
## 8 2020-01-29 Canada 0
## 9 2020-01-30 Canada 0
## 10 2020-01-31 Canada 0
การ subset โดยใช้พิกัดและค่าของข้อมูลที่เฉพาะเจาะจง
บางครั้ง เราไม่เพียงต้องการแถวและคอลลัมภ์ แต่เรายังต้องการค่าที่เฉพาะเจาะลงไปใน dataset เช่น ต้องการให้ country มีเพียง Canada เราสามารถเรียกพิกัดและข้อมูลนั้น ๆ ได้ โดยใช้การ subset หรือจะเรียกว่าการหั่น (indicing) การกรอง (filtering) ก็ได้เหมือนกัน โดย
-
การเขียน logic :
ชื่อไฟล์[ชื่อไฟล์$ชื่อคอลลัมภ์ที่ต้องการ == ค่าข้อมูลที่ต้องการ, ] -
subset : การใช้คำสั่ง
subset()ของBase R
# method a.
Covid <- Data[Data$country == "Canada", ]
head(Covid)
## date province country cases population
## 1 2020-01-22 Alberta Canada 0 4413146
## 2 2020-01-23 Alberta Canada 0 4413146
## 3 2020-01-24 Alberta Canada 0 4413146
## 4 2020-01-25 Alberta Canada 0 4413146
## 5 2020-01-26 Alberta Canada 0 4413146
## 6 2020-01-27 Alberta Canada 0 4413146
tail(Covid)
## date province country cases population
## 417086 2021-10-08 <NA> Canada 0 37855702
## 417087 2021-10-09 <NA> Canada 0 37855702
## 417088 2021-10-10 <NA> Canada 0 37855702
## 417089 2021-10-11 <NA> Canada 0 37855702
## 417090 2021-10-12 <NA> Canada 0 37855702
## 417091 2021-10-13 <NA> Canada 0 37855702
summary(Covid)
## date province country
## Min. :2020-01-22 Alberta : 1262 Length:20823
## 1st Qu.:2020-06-27 British Columbia: 1262 Class :character
## Median :2020-12-02 Diamond Princess: 1262 Mode :character
## Mean :2020-12-02 Grand Princess : 1262
## 3rd Qu.:2021-05-09 Manitoba : 1262
## Max. :2021-10-13 (Other) :13882
## NA's : 631
## cases population
## Min. :-1405971 Min. : 38780
## 1st Qu.: 0 1st Qu.: 158158
## Median : 0 Median : 977457
## Mean : 82 Mean : 4209062
## 3rd Qu.: 5 3rd Qu.: 5110917
## Max. : 23848 Max. :37855702
## NA's :3786
# method b.
Covid_canada <- subset(Covid, country == "Canada")
head(Covid_canada)
## date province country cases population
## 1 2020-01-22 Alberta Canada 0 4413146
## 2 2020-01-23 Alberta Canada 0 4413146
## 3 2020-01-24 Alberta Canada 0 4413146
## 4 2020-01-25 Alberta Canada 0 4413146
## 5 2020-01-26 Alberta Canada 0 4413146
## 6 2020-01-27 Alberta Canada 0 4413146
tail(Covid_canada)
## date province country cases population
## 417086 2021-10-08 <NA> Canada 0 37855702
## 417087 2021-10-09 <NA> Canada 0 37855702
## 417088 2021-10-10 <NA> Canada 0 37855702
## 417089 2021-10-11 <NA> Canada 0 37855702
## 417090 2021-10-12 <NA> Canada 0 37855702
## 417091 2021-10-13 <NA> Canada 0 37855702
summary(Covid_canada)
## date province country
## Min. :2020-01-22 Alberta : 1262 Length:20823
## 1st Qu.:2020-06-27 British Columbia: 1262 Class :character
## Median :2020-12-02 Diamond Princess: 1262 Mode :character
## Mean :2020-12-02 Grand Princess : 1262
## 3rd Qu.:2021-05-09 Manitoba : 1262
## Max. :2021-10-13 (Other) :13882
## NA's : 631
## cases population
## Min. :-1405971 Min. : 38780
## 1st Qu.: 0 1st Qu.: 158158
## Median : 0 Median : 977457
## Mean : 82 Mean : 4209062
## 3rd Qu.: 5 3rd Qu.: 5110917
## Max. : 23848 Max. :37855702
## NA's :3786
identical(Covid, Covid_canada)
## [1] TRUE
การเรียกข้อมูลที่มีขนาดใหญ่ออกมาดู เราอาจใช้คำสั่ง head() หรือ tail()แทนการ print()หรือเรียกชื่อไฟล์ออกมาทั้งไฟล์ก็ได้นะคะ หรืออาจใช้คำสั่ง summary()เพื่อดูสถิติเชิงพรรณาคร่าว ๆ
Noted คำสั่ง identical() ทดสอบว่าวัตถุสองชนิดมีลักษณะเหมือนกันทุกประการไหม
นอกจากนี้แล้ว เรายังสามารถเขียนเงื่อนไขการคัดกรองข้อมูลแบบรวบยอดได้โดยการนำสัญลักษณ์ | (or; หรือ) และ & (and; และ) ไปเขียนใน function อย่างไรก็ตาม ความเข้าใจในการคัดกรองตรรกะเป็นเรื่องสำคัญ ซึ่งเราจะได้เรียนรู้ต่อไปค่าา
การใช้สัญลักษณ์ตรรกะ (และ/หรือ) ใน R
โดยทั่วไปแล้ว การที่เราคัดกรองข้อมูลจะมีความเข้าใจพื้นฐาน โดยสามารถคิดตามจากภาพด้านล่างนี้
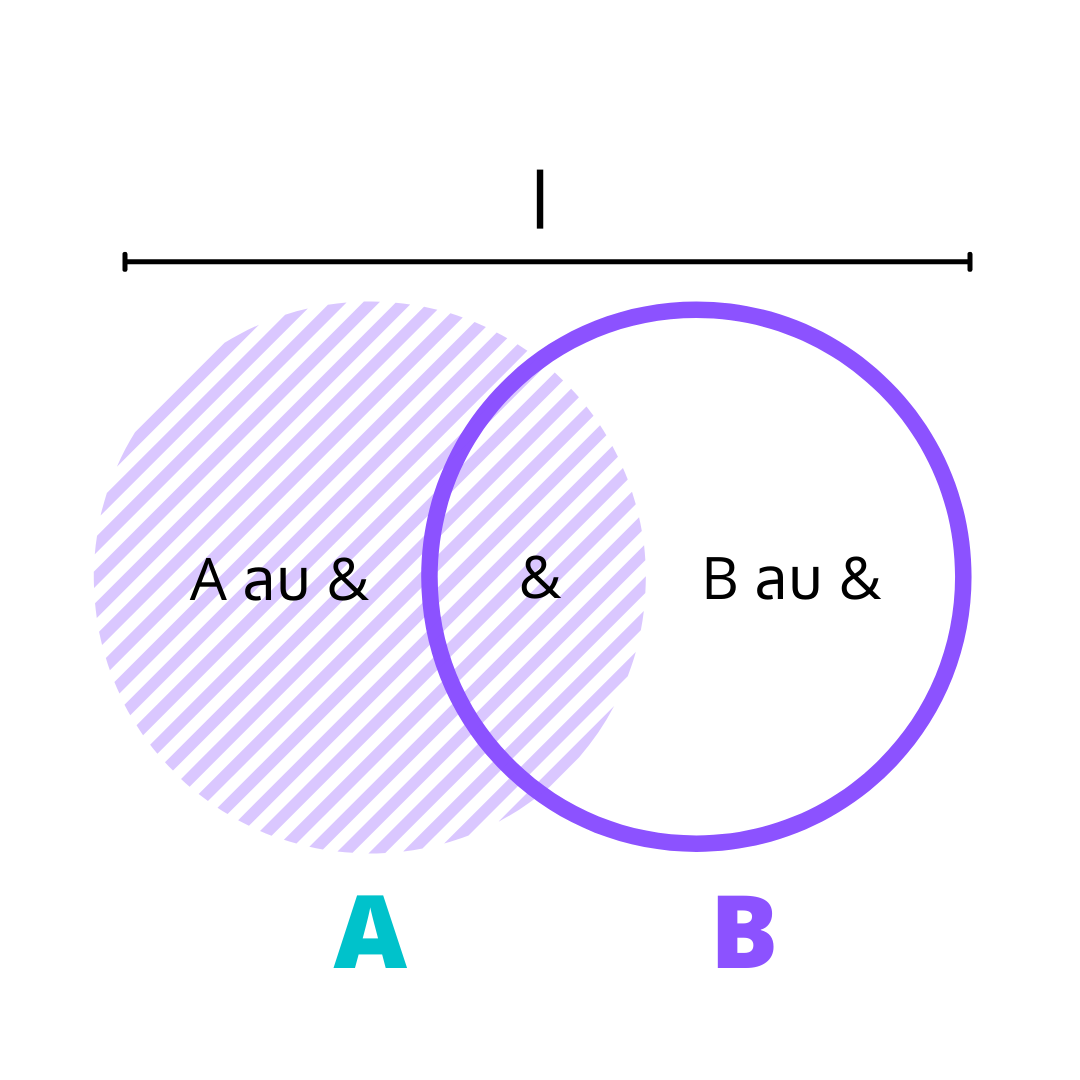
สมมติว่ามี data 2 ชุด เราต้องการเลือก ชุดข้อมูลบางชุดใน A และ ชุดข้อมูลบางชุดใน B ถ้าเราต้องการทั้งหมด เราจะใช้ หรือ สัญลักษณ์ | ในสมการ
แต่หากว่าเราต้องการ data ชุดข้อมูลบางชุดใน A แต่ชุดข้อมูลนี้ต้องปรากฎพร้อมกันใน B ด้วย เราจะใช้ และ สัญลักษณ์&ในสมการ
เช่น เราต้องการ country คือ Canada และ Thailand และทั้ง Canada และ Thailand จะต้องมีผู้ติดเชื้อเกิน 20 ราย
Covid_th_can <- Data[Data$country == "Canada" | Data$country == "Thailand", ]
head(Covid_th_can)
## date province country cases population
## 1 2020-01-22 Alberta Canada 0 4413146
## 2 2020-01-23 Alberta Canada 0 4413146
## 3 2020-01-24 Alberta Canada 0 4413146
## 4 2020-01-25 Alberta Canada 0 4413146
## 5 2020-01-26 Alberta Canada 0 4413146
## 6 2020-01-27 Alberta Canada 0 4413146
Covid_th_can_20 <- Covid_th_can[Covid_th_can$cases >= 20, ]
head(Covid_th_can_20)
## date province country cases population
## 57 2020-03-18 Alberta Canada 23 4413146
## 58 2020-03-19 Alberta Canada 22 4413146
## 59 2020-03-20 Alberta Canada 27 4413146
## 60 2020-03-21 Alberta Canada 49 4413146
## 61 2020-03-22 Alberta Canada 64 4413146
## 62 2020-03-23 Alberta Canada 42 4413146
Noted หากผู้ใช้ชำนาญแล้วแนะนำให้เขียนอยู่ในบรรทัดเดียวกันเลยค่า
ทั้งนี้ หากเราอยากนับจำนวนวันที่เคสติดเชื้อมากกว่า 20 รายใน Canada และ Thailand เราสามารถใช้คำสั่ง table() โดยระบุตัวแปรกลุ่มที่เราต้องการ
table(Covid_th_can_20$country)
##
## Canada Thailand
## 3856 602
และถ้าหากเราต้องการค่าเฉลี่ยเคสที่ติดโควิดใน Canada และ Thailand ในช่วงเวลาใน dataset เราสามารถหาได้โดยการใช้คำสั่งพื้นฐานของ R คือ mean()
mean(Covid_th_can_20$cases)
## [1] 1095.29
sd(Covid_th_can_20$cases)
## [1] 2591.22
median(Covid_th_can_20$cases)
## [1] 250
sqrt(mean(Covid_th_can_20$cases))
## [1] 33.09516
ข้อควรระวังคือ การหาค่าเฉลี่ยดังกล่าวคือการหาค่าเฉลี่ยรวมของ Canada และ Thailand ค่า หากทบทวนการ subset ด้านบน เราสามารถแยก data ของ Canada และ Thailand ออกจากกันได้ และหาค่าเฉลี่ย แต่เดี๋ยวเราจะได้เริ่มใช้ packages ที่ให้ข้อมูลเชิงซับซ้อนได้มากขึ้นในบทต่อไป :)
Happy Coding ka กลับไปที่ datastist.com